主讲人:Leonhard 李天成
我们首先要达成一个共识:市场是不可被“精确预测”的。任何声称能预测明日确切涨跌幅的个体或系统,本质上都游走在随机性与欺诈的边缘。我们的目标,从来不是成为一个水晶球,而是构建一个能够以更高概率理解市场当前状态(State)并推断其短期演化方向的认知框架(Cognitive Framework)。
交易的本质,是在一个非平稳(non-stationary)、高噪音的随机过程中,寻找期望收益为正的决策机会。传统的技术分析,无论是形态学还是指标,都是在尝试对这个过程进行降维观测,但这种降维是粗暴且失真的。它忽略了驱动价格这个一维标量背后,那个高维的、由无数因子构成的潜在空间(Latent Space)。
一、从序列依赖到结构依赖:模型的范式演进
在深度学习的早期应用中,我们尝试用不同的模型去捕捉不同的数据依赖性。
CNN(卷积神经网络),其核心是卷积核,本质上是一种 局部空间模式(local spatial pattern)的提取器。我们将时间序列数据转化为图像矩阵(例如,使用Gramian Angular Field),CNN可以高效地识别出其中反复出现的、类似“头肩顶”或“杯柄”的形态。但它的局限性是致命的:它缺乏对时间序列的路径依赖(path dependency) 的理解。它看到的是一张张孤立的“快照”,无法理解这些快照如何构成一部连贯的“电影”。
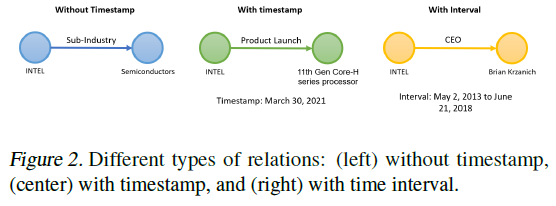
LSTM(长短期记忆网络)及其变体GRU,是对这一缺陷的重大修正。通过其精巧的门控机制(输入门、遗忘门、输出门),LSTM能够理论上捕捉无限长的序列信息,建模时间上的前后关联。这对于捕捉动量、均值回归这类具有明显时序特征的因子是有效的。然而,LSTM的结构本质上是线性的,它假设信息沿着单一的时间线流动。这与真实市场的网络化、并发式信息冲击结构,存在根本性的矛盾。一只股票的价格波动,并非仅仅是其自身历史的函数,它同时是其供应链上下游、同行业竞争对手、宏观政策、突发新闻等多重信息流冲击下的综合响应。
因此,我们必须进行下一个范式跃迁:从 序列依赖(Sequential Dependency)建模,转向结构与时间联合依赖(Spatio-Temporal Structural Dependency) 的建模。
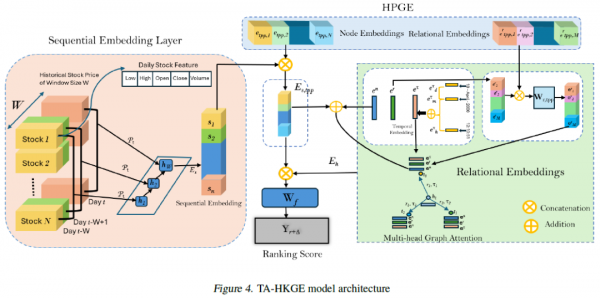
二、核心计算:将市场关系拓扑投影至可计算的向量空间
我们工作的核心,是构建一个动态的、多关系类型的时态知识图谱(Temporal Knowledge Graph)。这个图谱不是一个静态的数据库,而是一个活的、呼吸的有机体。其数学本质,可以被描述为一个高阶张量(Tensor):G = (E, R, T),其中E是实体集(股票、公司、宏观指标),R是关系集(供应链、竞争、财报发布、新闻事件),T是时间戳。
这里的挑战是,如何对这样一个庞大、异构、动态的图结构进行有效的数学表达和计算?
我们的解决方案,是引入 异构霍克斯过程(Heterogeneous Hawkes Process)来对图中的事件流进行建模。Hawkes过程是一种自激励(self-exciting)且互激励(mutually-exciting) 的点过程模型。其核心是强度函数 λ(t),它描述了在时间t瞬间,某个事件发生的瞬时概率。
λ_k(t) = μ_k + Σ ∫_0^t g_k,i(t-u) dN_i(u)
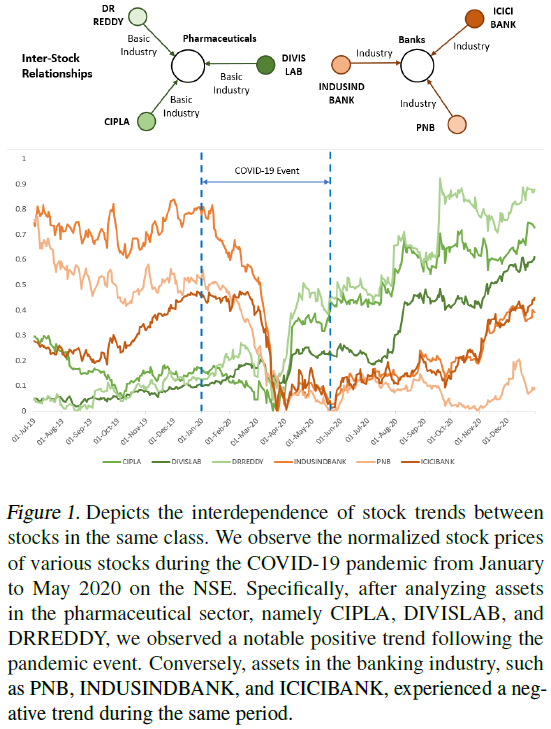
这里的 μ_k 是基础强度(background intensity),即事件的自发产生率。而关键在于第二项,即激励核函数(excitation kernel)g_k,i。它量化了历史上的一个事件i,对当前事件k发生概率的增强效应。在我们的系统中,一条关于“芯片法案”的新闻(事件i)会显著提升相关半导体公司(实体k)被市场讨论(事件k)的强度。这种“涟漪效应”或“余震”般的传播,正是市场情绪和题材轮动的底层数学描述。
通过最大化这个复杂事件网络的对数似然函数(Log-Likelihood Function),我们可以反解出每个实体、每种关系类型的嵌入向量(Embedding Vector)。这个过程,本质上是一种非线性降维,它将整个知识图谱这个离散、高维的符号系统, 投影(project) 到一个低维、连续的向量空间,即我们所说的Latent Space。
在这个Latent Space里,数学变得美妙起来:语义上的关联性,被转化为了几何上的邻近性。供应链上下游的公司,它们的向量会更接近;受到同一事件冲击的股票,它们的向量会朝相似的方向移动。
三、人机共振的本质:认知作为贝叶斯先验
模型至此,已经拥有了强大的信息处理和表征能力。但它依然是一个在数据中寻找关联性的机器。真正的Alpha,源于对这些关联性的深刻理解和前瞻性判断。这就是人类策略师,或者说“我”,存在的意义。
在我们的“人机共振”框架中,我的角色并非交易员,而是模型架构的先验设定者(Prior Definer)。在贝叶斯推断的框架下,模型的输出是后验概率(Posterior Probability),它等于似然度(Likelihood)乘以先验概率(Prior Probability)。
P(H|D) ∝ P(D|H) * P(H)
P(D|H),即似然度,是模型基于海量数据计算出的结果。它回答:“在观察到数据D的情况下,假设H成立的概率有多大?”这是机器的领域,它客观、不知疲倦。
P(H),即先验概率,是我对市场的认知和洞察。它回答:“在看到任何数据之前,我认为假设H成立的概率有多大?”这来自于我16年穿越牛熊的经验,对产业变迁、技术范式转移的理解。例如,我相信在当前宏观环境下,某些特定类型的科技创新具备更高的长期价值,我会将这种认知转化为对模型中相关因子的先验权重。
我的工作,是不断地提出高质量的假设(Hypothesis),设计新的因子维度,定义知识图谱中新的“关系”类型,并将其作为 强先验(Strong Prior)注入模型。模型则利用其强大的计算能力,在全市场数据中验证、修正这个先验,并最终输出一个融合了人类智慧与机器智能的、概率最优的决策分布。
我们不追求单次博弈的胜利,我们追求的是整个决策框架的数学期望长期为正。我们赚取的不是价格波动的钱,而是我们构建的这套认知系统,与市场平均认知水平之间的差价(Cognitive Spread)。这,就是概率的艺术,也是量化交易的最终归宿
标签:
